


Wir liefern schneller als alle anderen!
Wir digitalisieren deine manuellen Abläufe - damit du Zeit und Geld sparst.
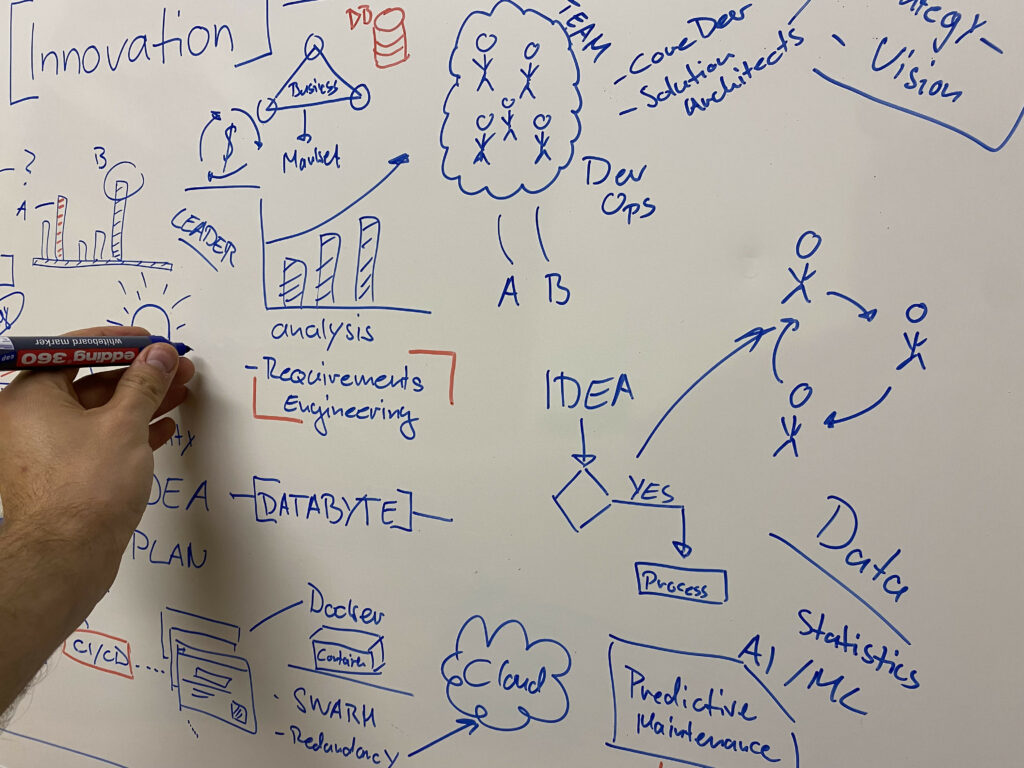
Was uns auszeichnet...
Kundennah
Wir entwickeln gemeinsam mit dem Kunden.
Dies schafft einen grossen Mehrwert!
Erfolg mit System
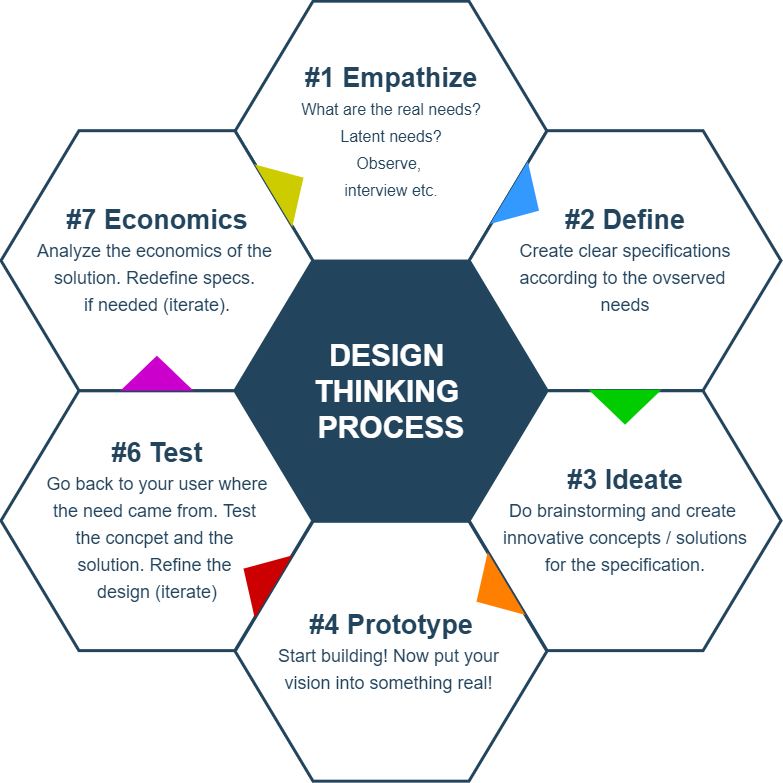
Durch den Einsatz etablierter Methodiken wie z.B. Design Thinking, sind wir sehr effizient in der Erarbeitung sowie Umsetzung neuer Ideen.

Prototyping
Neue Ideen werden bei uns in wenigen Wochen bis Tagen umgesetzt!
Dadurch kannst du bereits nach kurzer Zeit den Mehrwert unserer Arbeit sehen.
Vertraue unserer Erfahrung!
Wir bringen dein Unternehmen weiter.
Wie wir arbeiten
Zu beginn starten wir mit einem kostenlosen Erstgespräch.
Hier prüfen wir das gemeinsame Potential.
Hier prüfen wir das gemeinsame Potential.
01
Erstgespräch
Zuerst planen wir ein erstes kennenlernen. Hier finden wir gemeinsam heraus, wo die Reise hingehen könnte. Dies ist ohne Kosten für dich – das ist selbstverständlich!
02
Bedarfsanalyse
In einem zweiten Schritt werden wir gemeinsam den Bedarf und das Potential möglicher Digitalisierungen untersuchen
03
Zielsetzung
Wir erarbeiten nun ein Gesamtkonzept und zeigen auf, wie wir effizient die gesetzten Ziele erreichen werden.
04
Implementierung
Nun setzen wir die getroffenen Entscheidungen um und du wirst bereits nach kurzer Zeit Erfolge sehen! Teilweise bereits nach wenigen Tagen bis Wochen!
05
Resultate
Auch nach dem Projekt sind wir für dich da. Erweiterungen sind jederzeit möglich und auch bei Fragen sind wir immer erreichbar.
Agil und mit Co-Create zum Ziel!
Bei uns steht der Kunde im Zentrum. Wir entwickeln gemeinsam mit dir, unter Verwendung eines Agilen Ansatzes. Damit siehst du die Ergebnisse bereits nach kurzer Zeit.
Die Vorteile unserer Kunden
Zeit gespart
Durch Automatisierung spartst du jeden Tag Zeit. Mit der gewonnen Zeit kannst du z.B. neue Kunden aquirireren.
Reduzierte Fehler
Digitalisierte Abläufe führen zu weniger Fehlern, da die Prozesse klar geregelt sind. Beispielsweise automatische Bestellabwicklung.
Erhöhte Effizienz
Dank klaren Abläufen und automatisierter Ausführung werden deine Prozesslaufzeiten planbarer und effizienter.
In einem Unternehmen können manuelle Prozesse zu Fehlern, langsamen Reaktionszeiten und einem Verlust Geld führen. Diese Herausforderungen können das Wachstum des Unternehmens beeinträchtigen und die Produktivität beeinträchtigen.
Wir von Databyte, haben uns daher auf die Optimierung von Geschäftsprozessen spezialisiert. Mit einem innovativen Ansatz, der Design Thinking und Co-Creation kombiniert, arbeiten unsere Experten von Databyte mit dir zusammen, um gemeinsam massgeschneiderte Lösungen für dein Problem zu entwickeln.
Durch die Zusammenarbeit mit uns können wir effiziente, automatisierte Lösungen umsetzen. Dies ermöglicht es deinem Unternehmen, Zeit, Geld und Ressourcen zu sparen, die für wichtigere Aufgaben genutzt werden können.
Dank der Zusammenarbeit mit Databyte kann dein Unternehmen schneller wachsen und sich weiterentwickeln, während gleichzeitig Zeit und Geld gespart wird.
Wie du profitieren kannst
Buche ein Meeting
Vereinbare einen Termin mit uns, damit wir gemeinsam definieren können was deine Ziele sind.
Plan erstellen
Nach dem Erstgespräch erstellen wir eine Roadmap um deine Ziele zu erreichen.
Resultate sehen
Erhalte innert kürzester Zeit bereits erste Resultate und spare Zeit und Geld.